JS中常用的编码格式
Unicode:规定将全球的语言纳入一个字符集,即每种语言中的每个字符都有一个唯一的编码,以便可以跨平台,跨系统,跨语言而不冲突,且不用安装特定的字符集来解释某个国家的语言。
而UTF-8和UTF-16和UTF-32则是对Unicode字符集的具体实现的方法。
UTF-8: 在1-4个字节中变长表示,比如数字或字母采用1个字节表示,在node中,一般默认采用该方法。
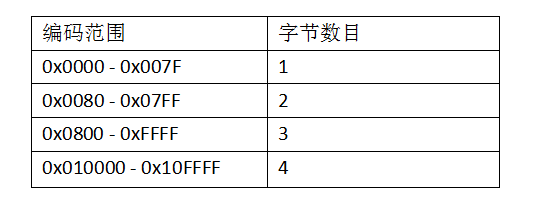
UTF-16: 采用2字节或4字节变长表示。
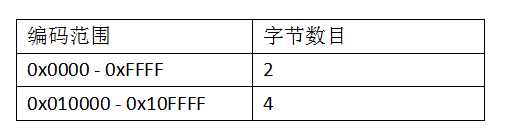
UTF-32: 全部用4字节表示,不兼容ASCII编码,容易浪费空间。
UCS-2 : JS里的编码表示,采用固定2个字节,后来被UTF-16取代了,也就是说UTF-16将UCS-2包含在其中。所以现在JS也就是采用UTF-16表示。
由于UTF-16一般是2个字节表示的,所以对于单字母,比如'a' 0x61只需占一个字节,那么是采取[0x00,0x61]还是[0x61,0x00]的表示表示呢,则设计到2种表示法,LE和BE,而对于UTF-8则没有这种顾虑.
- UTF-16LE:
LE是指little endian, 表示高地址放高位字节,a字符用LE表示则为[0x61,0x00] - UTF-16BE:
BE是指Big endian, 表示低地址存放高位字节,符合我们平常的阅读习惯,用BE表示则为[0x00, 0x61]
那么在文件传输中如何表示该文件是什么编码格式呢?
使用BOM(byte-order mark)即字节顺序标记,表示该文件是LE还是BE,常被用来当做标示文件是以UTF-8、UTF-16或UTF-32编码的标记,在文件的开头会有如下编码标识:
UTF-16大端表示:[0xFE, 0xFF],小端则是:[0xFF, 0xFE]UTF-32大端表示:[0x00 0x00 0xFE 0xFF],小端则是:[0xFF 0xFE 0x00 0x00]- 而在
UTF-8里的表示则是:[0xEF 0xBB 0xBF], 一般是用来标示该文件是UTF-8编码,而不用来说明字节顺序。
汉字的长度在js中的长度是1,如 '好'.length = 1; 这里的1表示一个编码单元,而 不是占用的字节长度 。
如果想要计算字符串(含有汉字和字符)占的字节长度,可以用如下代码表示:
1 | |
但是有一些生僻字是用4个字节表示的,即超过了0xFFFF,比如:’𠮷’,'𠮷'.length = 2; 由于一个编码单元不能表示,所以需2个编码单元来表示,但是长度是2是错误的,在es5中是只能自己手动处理,但是在es6中我们可以使用Array.from('𠮷').length 来正确处理,输出1。
匹配所有字符是否都是汉字,如下所示:
1 | |
一些常用其他编码术语:
ASCII: 一个字节,128位字母和数字表示。
Base64:是一种基于64个可打印字符来表示二进制数据的表示方法
Latin1: 单字节编码,向下兼容ASCII。
GBK:汉字内码扩展的规范,兼容ASCII,不支持韩国字,如果程序只是面向汉字,可以采用该编码。
Binary:二进制
HEX: 十六进制
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!